OS:Ubuntu 14.04
java8/Elasticsearch2.1.0/Kibana4.3.0で構築。
https://github.com/maar4569/dockerfiles-sample/tree/master/elastic
さらにネットワークまわり(主にIPアドレスだが)を編集するコマンドを追加したのが
これ。
https://github.com/maar4569/dockerfiles-sample/blob/master/elastic_dev/Dockerfile
これは前者のイメージをベースに作成したDockerイメージ。
2015年12月12日土曜日
2015年12月11日金曜日
スペースを含むkey/value形式のデータを抽出する
splunkではkey=val形式のイベントを検出すると自動的に抽出する。
しかしvalの値にスペースを含むと正しく抽出することができない。
例えば、ダブルクォテーションで括られていれば抽出可能だが、
無い場合抽出できない。
msg="hello world" =>hello worldを抽出
msg=hello world => helloだけ抽出。
正しく抽出するにはtransform.confのREGEXを使用して抽出する。
例えば以下のようなイベントが存在するとする。
この時以下のように設定する。
props.conf
[mysourctype]
REPORT-mykvformat=my_kv
transforms.conf
[my_kv]
REGEX=¥s(?<_KEY_1>¥w+)=(?<_VAL_1>¥w+)¥s¥w+=
splunkを再起動する。
しかしvalの値にスペースを含むと正しく抽出することができない。
例えば、ダブルクォテーションで括られていれば抽出可能だが、
無い場合抽出できない。
msg="hello world" =>hello worldを抽出
msg=hello world => helloだけ抽出。
正しく抽出するにはtransform.confのREGEXを使用して抽出する。
例えば以下のようなイベントが存在するとする。
この時以下のように設定する。
props.conf
[mysourctype]
REPORT-mykvformat=my_kv
transforms.conf
[my_kv]
REGEX=¥s(?<_KEY_1>¥w+)=(?<_VAL_1>¥w+)¥s¥w+=
splunkを再起動する。
機械学習で使うライブラリ(numpy/scipy/matplotlib)をインストールしたDockerコンテナを作った
OSはCentOS 7ベースで、
numpy、scipy、matplotlibをインストールしたDockerコンテナを作成。
Dockerfileは以下のとおり。
https://github.com/maar4569/dockerfiles-sample/blob/master/machinelearning/Dockerfile
最低限のライブラリをインストールしただけなので、コードを各場合は必要に応じてインストールすること。
numpy、scipy、matplotlibをインストールしたDockerコンテナを作成。
Dockerfileは以下のとおり。
https://github.com/maar4569/dockerfiles-sample/blob/master/machinelearning/Dockerfile
最低限のライブラリをインストールしただけなので、コードを各場合は必要に応じてインストールすること。
2015年8月10日月曜日
指定した時間の範囲で集計処理する
まとめ
・指定した時間の範囲を生成するにはgentimesを使う。
・gentimesで生成した時間の範囲をmapコマンドに渡してループ処理する。
使用するシーン
通常1日は0時から始まり23:59:59までと考えるが、業務によって1日の始まりを0:00AM以外で規程することがある。
例えば2:00AMを1日の始まりとした場合、2015/08/01を2015/08/01 02:00:00 〜 2015/08/02 01:59:59として考える。
timechartで集計すると1日の始まりは0:00AMとなるので、期待する結果が得られない。
この時gentimesコマンドを使用すると1日の始まりを2:00AMと規程して、時間の範囲を作成することができる。unixtimeとhuman readableな時間が返る。

このうちstarttime、endtimeフィールドをトークンでmapコマンドに渡す事により、
各時間の範囲のサーチができる。
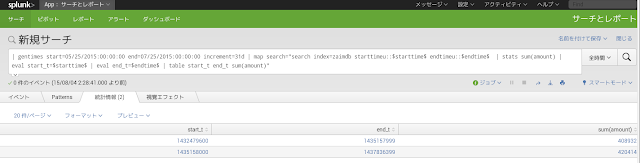
以下は5/25から7/25日のデータを25日を基点に集計したサンプル。(starttimeは)
最初の時間の範囲は5/25から6/24、2行目は6/25から7/24となっている。

上記のstarttimeフィールドとendtimeフィールドをmapコマンドにトークンで渡すと、
gentimesコマンドで取得した時間の範囲で集計している。
おわりに
mapコマンドにわたすトークンは時間でなくてもよいので、何かのリストを渡してループ処理したい場合など応用範囲は広いのではと思う。
・指定した時間の範囲を生成するにはgentimesを使う。
・gentimesで生成した時間の範囲をmapコマンドに渡してループ処理する。
使用するシーン
通常1日は0時から始まり23:59:59までと考えるが、業務によって1日の始まりを0:00AM以外で規程することがある。
例えば2:00AMを1日の始まりとした場合、2015/08/01を2015/08/01 02:00:00 〜 2015/08/02 01:59:59として考える。
timechartで集計すると1日の始まりは0:00AMとなるので、期待する結果が得られない。
この時gentimesコマンドを使用すると1日の始まりを2:00AMと規程して、時間の範囲を作成することができる。unixtimeとhuman readableな時間が返る。

このうちstarttime、endtimeフィールドをトークンでmapコマンドに渡す事により、
各時間の範囲のサーチができる。
以下は5/25から7/25日のデータを25日を基点に集計したサンプル。(starttimeは)
最初の時間の範囲は5/25から6/24、2行目は6/25から7/24となっている。

上記のstarttimeフィールドとendtimeフィールドをmapコマンドにトークンで渡すと、
gentimesコマンドで取得した時間の範囲で集計している。

おわりに
mapコマンドにわたすトークンは時間でなくてもよいので、何かのリストを渡してループ処理したい場合など応用範囲は広いのではと思う。
2015年5月20日水曜日
Splunkでサマリインデックスを使う
まとめ
・サマリインデックスを使うことで大量データであっても効率よくレポートが作成できる。
・レポートでは先頭にsiが付くsixxxxコマンドを使う。
サンプルデータを登録・設定する
まず以下のようなデータがインデックスに登録されていくものとする。
販売履歴のようなデータ。
フィールドは「タイムススタンプ、アイテム、価格」
<やりたいこと>
・週次で売上履歴のサマリを取得したい。ここでは価格の合計値。
・集計対象は前週の日曜日から土曜日とする。
<インデックスの登録されていくデータ>
2015-03-01 13:00:00,book,100
2015-03-02 11:00:00,book,200
2015-03-03 16:00:00,book,300
2015-03-04 10:00:00,eraser,400
2015-03-05 09:00:00,note,500
2015-03-06 08:00:00,note,600
2015-03-07 07:00:00,book,700
2015-03-08 16:00:00,book,800
2015-03-09 13:00:00,book,900
2015-03-10 14:00:00,book,1000
2015-03-11 22:00:00,pen,1100
2015-03-12 23:00:00,book,1200
2015-03-13 10:00:00,note,1300
2015-03-14 12:00:00,note,1400
2015-03-15 16:00:00,book,1500
2015-03-16 13:00:00,book,100
2015-03-17 11:00:00,book,200
2015-03-18 16:00:00,book,300
2015-03-19 10:00:00,eraser,400
2015-03-20 09:00:00,note,500
2015-03-21 08:00:00,note,600
2015-03-22 07:00:00,book,700
2015-03-23 16:00:00,book,800
2015-03-24 13:00:00,book,900
2015-03-25 14:00:00,book,1000
2015-03-26 22:00:00,pen,1100
2015-03-27 23:00:00,book,1200
2015-03-28 10:00:00,note,1300
2015-03-29 12:00:00,note,1400
2015-03-30 16:00:00,book,1500
2015-03-31 16:00:00,book,1600
<事前の条件>
インデックス名
demo_alert
フィールド定義
$SPLUNK_HOME$/etc/system/local/props.confで以下のように定義しておく。
定義後はsplunkdの再起動を忘れない。
[demo_alert]
NO_BINARY_CHECK = true
SHOULD_LINEMERGE = false
category = Custom
pulldown_type = true
FIELD_NAMES = time,item,amount
disabled = false
TIME_FORMAT=%Y-%m-%d %H:%M:%S
MAX_DAYS_HENCE=7
サマリインデックスを作成する
サマリインデックスは通常のインデックスを作成する場合と同じ方法。
サマリインデックスを作成するための特別な手順はない。
インデックス名はdemo_alert_sumとして作成する。
レポートを作成する
ここで毎週スケジューリングして週次の集計値を作成するための
設定を行う。サマリインデックスに集計値を格納する部分もここで行う。
1.[設定]-[サーチ、アラート、レポート]を選択する
2.[新規追加]ボタンをクリックする。
3.サーチ文字列を設定する。ここで記述するコマンドはサマリインデックス用の
コマンドを使う。先頭にsiが付くコマンド。例えばsistatsなど。
3-1.サーチ文字列を設定する
index="demo_alert" | sistats sum(amount)
ここでは、amountの合計を取得する。
開始時刻と完了時刻が-w@w0、@w0となっている。
これはサーチ対象とする時間の範囲を指定している。この表現を細かく見ていく。
まず開始時刻だが、[-w@w0]は先週の日曜日を示す。@より前の部分[-w]は先週、@移行の部分w0は日曜日を示す。(0が日曜で、1が月曜、、、、6が土曜日となる。)
一方[@w0]は今週の日曜日を示す。今週を示すのであれば@より前の部分の定義は不要だ。
開始時刻と完了時刻は以上・未満の関係になるため、
先週日曜の00:00:00から先週土曜の23:59:59までを意味する。
時間に関する表現は以下のURLを参照。
http://docs.splunk.com/Documentation/Splunk/6.2.2/SearchReference/Commontimeformatvariables
3-2.[このサーチをスケジュールする]にチェックを入れる。

3-3.スケジュールタイプで[基本]を選択する
3-4.実行間隔を選択する。ここでは[週(毎土曜日の午前0時)]を選択する。
選択肢はいくつか用意されているが、任意のタイミングで実施したい場合は、
cronと同じ形式で設定することも可能。

サマリインデックスを確認する
スケジュールどおりに動作し、サマリインデックス[demo_alert_sum]を開くと、下記のように集計値が保存される。
1行目はXからXまでのフィールド「amount」の集計で3600
2行目はXからXまでのフィールド「amount」の集計で3600
3行目はXからXまでのフィールド「amount」の集計で7200
上記のログデータとつき合わせて確認するとちゃんと週次で集計されていることが
分かる。
格納されている情報を見るとわかるが、集計元のイベントは無くsixxxxコマンドで集計した統計情報だけである。

集計対象の時間はinfo_min_time,info_max_timeフィールドに値が登録される。
unixtimeなのでわかりにくいので、わかりやすく変換してみる。
unixtimeを変換し、変換した値を新たなフィールドとして追加するためには、evalコマンドとsrftimeコマンドを使用する。
例)
eval info_min_time2=strftime("%Y-%m-%d %H %M %S")
それぞれの集計データが
2015/3/8(日) 00:00:00以上、2015/3/15(日) 00:00:00未満

終わりに
大量データから集計値を作成する場合、長期間に渡るデータを1回の操作で抽出するのは、
非効率的だし、処理をするのに多くのリソースを必要とする。要は作成に時間がかかりすぎる。ユーザ要件の中で例えば1ヶ月に1回のレポート作成があるのならば、
週次や日次で集計データを作成しておくと効率的にレポートを作成することができる。
レポートとサマリインデックスを併用するとそれが実現できる。
・サマリインデックスを使うことで大量データであっても効率よくレポートが作成できる。
・レポートでは先頭にsiが付くsixxxxコマンドを使う。
サンプルデータを登録・設定する
まず以下のようなデータがインデックスに登録されていくものとする。
販売履歴のようなデータ。
フィールドは「タイムススタンプ、アイテム、価格」
<やりたいこと>
・週次で売上履歴のサマリを取得したい。ここでは価格の合計値。
・集計対象は前週の日曜日から土曜日とする。
<インデックスの登録されていくデータ>
2015-03-01 13:00:00,book,100
2015-03-02 11:00:00,book,200
2015-03-03 16:00:00,book,300
2015-03-04 10:00:00,eraser,400
2015-03-05 09:00:00,note,500
2015-03-06 08:00:00,note,600
2015-03-07 07:00:00,book,700
2015-03-08 16:00:00,book,800
2015-03-09 13:00:00,book,900
2015-03-10 14:00:00,book,1000
2015-03-11 22:00:00,pen,1100
2015-03-12 23:00:00,book,1200
2015-03-13 10:00:00,note,1300
2015-03-14 12:00:00,note,1400
2015-03-15 16:00:00,book,1500
2015-03-16 13:00:00,book,100
2015-03-17 11:00:00,book,200
2015-03-18 16:00:00,book,300
2015-03-19 10:00:00,eraser,400
2015-03-20 09:00:00,note,500
2015-03-21 08:00:00,note,600
2015-03-22 07:00:00,book,700
2015-03-23 16:00:00,book,800
2015-03-24 13:00:00,book,900
2015-03-25 14:00:00,book,1000
2015-03-26 22:00:00,pen,1100
2015-03-27 23:00:00,book,1200
2015-03-28 10:00:00,note,1300
2015-03-29 12:00:00,note,1400
2015-03-30 16:00:00,book,1500
2015-03-31 16:00:00,book,1600
<事前の条件>
インデックス名
demo_alert
フィールド定義
$SPLUNK_HOME$/etc/system/local/props.confで以下のように定義しておく。
定義後はsplunkdの再起動を忘れない。
[demo_alert]
NO_BINARY_CHECK = true
SHOULD_LINEMERGE = false
category = Custom
pulldown_type = true
FIELD_NAMES = time,item,amount
disabled = false
TIME_FORMAT=%Y-%m-%d %H:%M:%S
MAX_DAYS_HENCE=7
サマリインデックスを作成する
サマリインデックスは通常のインデックスを作成する場合と同じ方法。
サマリインデックスを作成するための特別な手順はない。
インデックス名はdemo_alert_sumとして作成する。
レポートを作成する
ここで毎週スケジューリングして週次の集計値を作成するための
設定を行う。サマリインデックスに集計値を格納する部分もここで行う。
1.[設定]-[サーチ、アラート、レポート]を選択する
2.[新規追加]ボタンをクリックする。
3.サーチ文字列を設定する。ここで記述するコマンドはサマリインデックス用の
コマンドを使う。先頭にsiが付くコマンド。例えばsistatsなど。
3-1.サーチ文字列を設定する
index="demo_alert" | sistats sum(amount)
ここでは、amountの合計を取得する。
開始時刻と完了時刻が-w@w0、@w0となっている。
これはサーチ対象とする時間の範囲を指定している。この表現を細かく見ていく。
まず開始時刻だが、[-w@w0]は先週の日曜日を示す。@より前の部分[-w]は先週、@移行の部分w0は日曜日を示す。(0が日曜で、1が月曜、、、、6が土曜日となる。)
一方[@w0]は今週の日曜日を示す。今週を示すのであれば@より前の部分の定義は不要だ。
開始時刻と完了時刻は以上・未満の関係になるため、
先週日曜の00:00:00から先週土曜の23:59:59までを意味する。
時間に関する表現は以下のURLを参照。
http://docs.splunk.com/Documentation/Splunk/6.2.2/SearchReference/Commontimeformatvariables
3-2.[このサーチをスケジュールする]にチェックを入れる。
3-3.スケジュールタイプで[基本]を選択する
3-4.実行間隔を選択する。ここでは[週(毎土曜日の午前0時)]を選択する。
選択肢はいくつか用意されているが、任意のタイミングで実施したい場合は、
cronと同じ形式で設定することも可能。
サマリインデックスを確認する
スケジュールどおりに動作し、サマリインデックス[demo_alert_sum]を開くと、下記のように集計値が保存される。
1行目はXからXまでのフィールド「amount」の集計で3600
2行目はXからXまでのフィールド「amount」の集計で3600
3行目はXからXまでのフィールド「amount」の集計で7200
上記のログデータとつき合わせて確認するとちゃんと週次で集計されていることが
分かる。
格納されている情報を見るとわかるが、集計元のイベントは無くsixxxxコマンドで集計した統計情報だけである。
集計対象の時間はinfo_min_time,info_max_timeフィールドに値が登録される。
unixtimeなのでわかりにくいので、わかりやすく変換してみる。
unixtimeを変換し、変換した値を新たなフィールドとして追加するためには、evalコマンドとsrftimeコマンドを使用する。
例)
eval info_min_time2=strftime("%Y-%m-%d %H %M %S")
それぞれの集計データが
2015/3/8(日) 00:00:00以上、2015/3/15(日) 00:00:00未満
2015/3/15(日) 00:00:00以上、2015/3/22(日) 00:00:00未満
の範囲のデータを対象にしていたことがわかる。
大量データから集計値を作成する場合、長期間に渡るデータを1回の操作で抽出するのは、
非効率的だし、処理をするのに多くのリソースを必要とする。要は作成に時間がかかりすぎる。ユーザ要件の中で例えば1ヶ月に1回のレポート作成があるのならば、
週次や日次で集計データを作成しておくと効率的にレポートを作成することができる。
レポートとサマリインデックスを併用するとそれが実現できる。
2014年11月26日水曜日
AMIにMechanizeをインストールする
AMIのruby環境はあまりパッケージがインストールされていないので、mechanizeのインストールにつまずくことがある。
なので、ここに一連の手順を残しておく。
rubyバージョン ruby 2.0.0p481
1.yum install ruby-devel
2.yum install gcc-c++.noarch
3.yum install libxslt-devel.x86_64
4.yum install patch.x86_64
以下のような nokogoriやmechanizeをインストールするときに
以下のようなメッセージが出で失敗する事があるので
必ずインストールする。
patch.logを見ると、パッチコマンドが見つからないという趣旨のエラーが出力されている。
Running 'patch' for libxml2 2.9.2... ERROR, review '/home/ec2-user/.gem/ruby /2.0/gems/nokogiri-1.6.4.1/ext/nokogiri/tmp/x86_64-redhat-linux-gnu/ports /libxml2/2.9.2/patch.log' to see what happened.
*** extconf.rb failed ***
Could not create Makefile due to some reason, probably lack of necessary
libraries and/or headers. Check the mkmf.log file for more details. You may
need configuration options.
5.gem install nokogiri
6.gem install mechanize
以上
なので、ここに一連の手順を残しておく。
rubyバージョン ruby 2.0.0p481
1.yum install ruby-devel
2.yum install gcc-c++.noarch
3.yum install libxslt-devel.x86_64
4.yum install patch.x86_64
以下のような nokogoriやmechanizeをインストールするときに
以下のようなメッセージが出で失敗する事があるので
必ずインストールする。
patch.logを見ると、パッチコマンドが見つからないという趣旨のエラーが出力されている。
Running 'patch' for libxml2 2.9.2... ERROR, review '/home/ec2-user/.gem/ruby /2.0/gems/nokogiri-1.6.4.1/ext/nokogiri/tmp/x86_64-redhat-linux-gnu/ports /libxml2/2.9.2/patch.log' to see what happened.
*** extconf.rb failed ***
Could not create Makefile due to some reason, probably lack of necessary
libraries and/or headers. Check the mkmf.log file for more details. You may
need configuration options.
5.gem install nokogiri
6.gem install mechanize
以上
2014年10月20日月曜日
ZaimApp for Splunk
Zaimに入力データをJson形式でインポートすればデータ解析ができる
SplunkのAppを作ってみた
Zaimは分析能力が乏しいことから分析能力が非常にすばらしいSplunkでの
利用を検討。
基本的にはJsonフォーマットによるインポートだが
CSVファイルでもinputs.confを調整すればいけるはず。
まずはベータとして。
https://github.com/maar4569/splunk_zaimapp
SplunkのAppを作ってみた
Zaimは分析能力が乏しいことから分析能力が非常にすばらしいSplunkでの
利用を検討。
基本的にはJsonフォーマットによるインポートだが
CSVファイルでもinputs.confを調整すればいけるはず。
まずはベータとして。
https://github.com/maar4569/splunk_zaimapp
登録:
コメント (Atom)